
This blog talks about ML project Lifecycle and it is part of the series Learning ML – Applied Way.
Who is this blog for?
ML beginners, MLEs, Applied scientists, Eng managers, Science managers, Product Managers, Executives, Data Analysts and Business System Analysts.
What will reader gain from this?
After reading this readers will be able to,
- Initiate and structure ML project
- Articulate the needs of a ML project
- Create a work break down structure of ML project
What makes this content essential?
ML development is not similar to traditional software development. Many companies and teams who start AI/ML projects, stuck in the midway or realising what they should have done in the beginning after spending months of efforts. This leads to chaos, panic and also mistrust in AI/ML solutions. This article talks about various phases and their lifecycle in a typical ML development.
ML Project lifecycle – 30000ft view
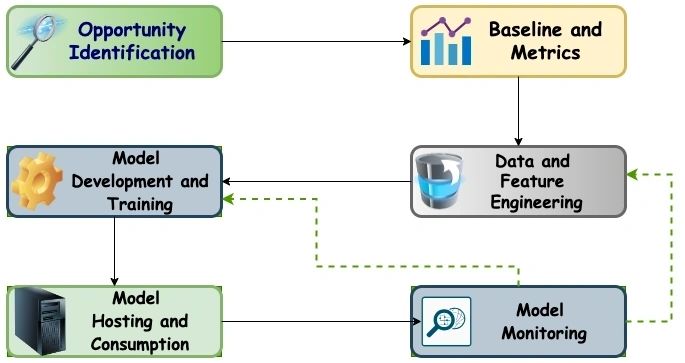
Dotted lines here represent next iteration on needed basis
Opportunity Identification phase
At the end of this phase there will be a business problem that needs ML solutions.
Identifying ML opportunities is a tricky space. Many problems are wrongly chosen as ML problems and got stuck in the development phase. This section explains few of the basic tenets that should be followed in identifying ML problems.
Tenet 1: We should not hunt for ML problems. Instead we should hunt for business opportunities and ML should be a natural solution to it. It sounds so simple right? With so much bragging around LLMs [when this article was written] and with the fear of missing out from leadership this is the hardest tenet to follow.
Tenet 2: Problems that are heuristically solvable should not be force fed to ML. Most of the times straight forward heuristics are not even analysed just to get an AI/ML badge in projects. There are also inverted scenarios where Engineers who hate ML [for some reason] tries to solve everything using heuristics and keep dismissing ML as an option.
This text is just an overview of tenets. Identifying AI/ML problems will be written as a detailed blog and will be linked here soon.
Baseline and Metrics
This is the most crucial phase in any AI/ML development and not covered in many of the ML text. Projects which failed to complete this phase properly will end up in failure 99% of the times. This phase will give us “Baseline Metric” and “Validation Data” for model evaluation. High level view of this phase is captured in below diagram.
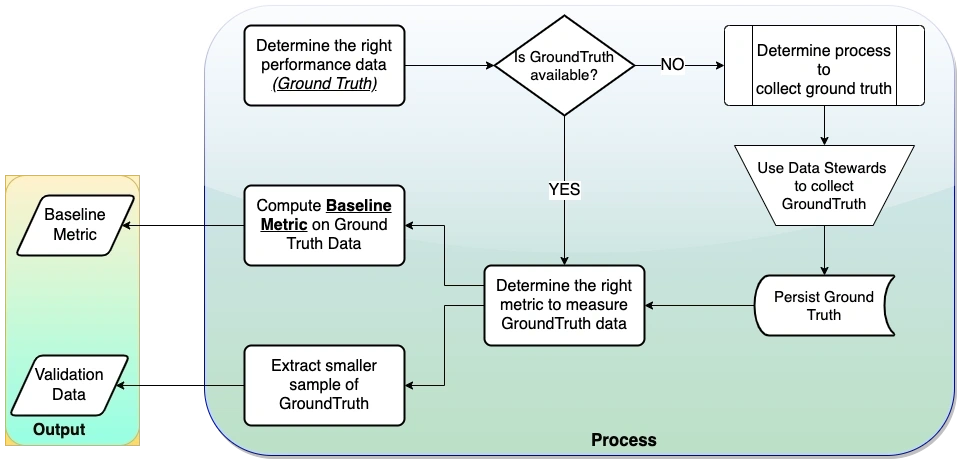
Determining Ground Truth
GroundTruth refers to the actual performance data of a system. It is based on the type of problem that is chosen.
Few examples for GroundTruth is given below.
If we would like to build a delivery time prediction for an online food ordering system, then GroundTruth will be the past deliveries’ turn around time.
If we are trying to build a troll detector in comments, then comments that are reported by users as troll or abusive will be the GroundTruth.
GroundTruth will not be readily available always. Best practices in such scenarios will be written as a separate blog and linked here soon.
Computing Baseline Metric
Baseline Metric is the measure of how current state of system is performing based on GroundTruth.
Won’t Baseline Metric and Model’s metric be the same?
Many times, Yes. Sometimes it won’t be. For example, Models used in recommendations engine are optimized for “Click Through Rate (CTR)” metric. However that is not the only performance metric which is used to asses recommendation engine. There are measures like engagement, retention rate, etc. Models may or may not be optimized on these. But recommendation systems will be assessed on these. Baseline metric at this phase will be the yardstick for the system performance not the models’.
There will be a detailed blog on GroundTruth and Metrics as part of the series. It will be linked here soon.
Data and Feature Engineering
Goals of this phase are,
- Identify the features or signals that are essential for the prediction task.
- Determine the transformations needed on the data.
- Determine the right representation of the data.
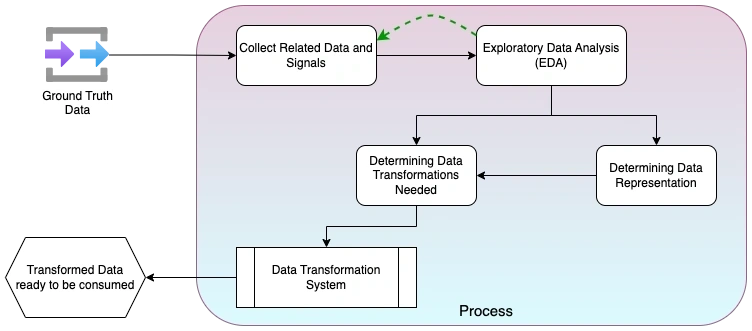
There is a dotted line from EDA to data collection because sometimes EDA can lead to more data discovery. In such cases the additional data and their signals need to be collected.
Exploratory Data Analysis (EDA)
EDA is a set of techniques that are used to see the features and characteristics of data with an open mind. John W Tukey who developed EDA techniques calls it as a detective work on data. There will be a separate blog(s) which will cover details of EDA in detail and will be linked here soon. After EDA, one should have identified the list of data features that are needed for the prediction task.
Data Transformation and Data representation
These are standard data preprocessing techniques. There are many reasons we do data transformations. Few of them are scaling, noise control, distribution change, etc., Detailed explanation of these reasons will be captured in a separate blog and will be linked here soon.
Model Development and Training
This is the phase where actual model building happens. Few critical steps in the model building is captured in the below diagram.
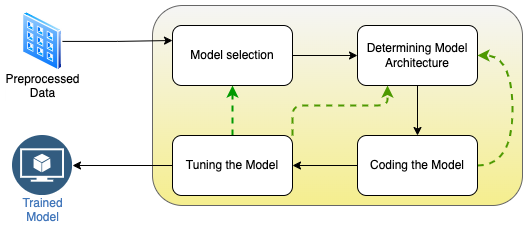
Dotted line here represents the model development iterations on needed basis.
We have given one liner description of work-items. Each work-item in this diagram deserves multiple blogs on itself. We will link them here soon.
Model selection – Determining the right model for the prediction task. We generally use our understanding from EDA to achieve this. Selecting AutoML vs manual model building happens here.
Model Architecture – This will be an iterative exercise during model development. Teams generally start with what they think is right and refine their judgement during the cycles of training and tuning.
Coding the model – This phase is intuitive yet it was explicitly mentioned because there are various techniques like auto tuning, training – test split that affects model’s performance.
Tuning the model – There are many automatic techniques to achieve this task. However manual data analysis is essential even on such scenarios to ensure model is generalized enough.
Model Hosting and consumption
There are various platforms like VertexAI, Sagemaker etc available to facilitate this process. Below diagram captures work items that are needed while consuming one such platform.
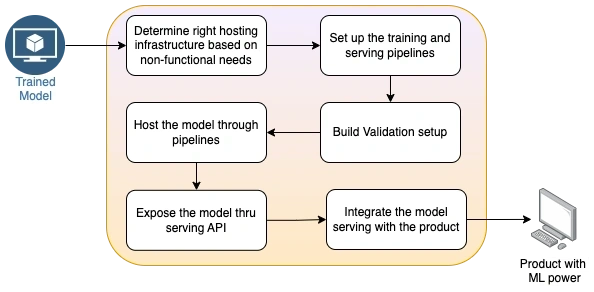
Since most of the work-items in the diagram are self explanatory we did not add separate description for them.
Best practices and efficient recommendations on those work items will covered as a separate blog and will be linked here soon.
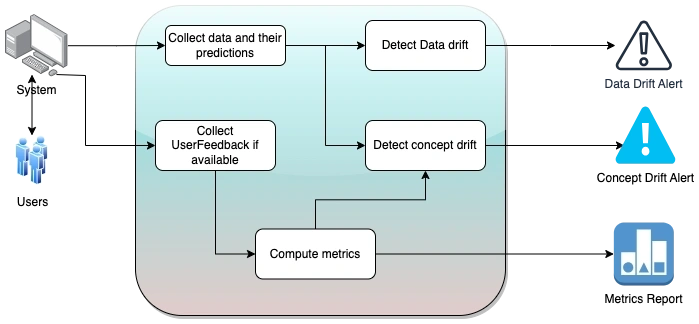
Model Monitoring
This is the most crucial phase for models that are getting into production. This topic deserves multiple blogs as many teams avoid this and realise their fault after a disaster. Main reason this phase should not be avoided is ” Models once trained and pushed into production need not perform continuously with same efficiency “
Why models won’t perform continuously?
This is the major difference between traditional software development and ML development. Teams are training the model and evaluating it in production based on the data awareness they have at that time. But this can change, mostly will change. If the data context changes then our model won’t perform as expected.
For example,
- Demand forecast system for hand sanitizers trained before 2020 would not have considered the demand increase due to Covid.
- Sudden craze of Dalgona coffee in internet search is also a data context change.
So the conclusion is data context can change anytime in production. If model is not monitored after rolled out to production, systems depending on the prediction of models will fail and could be detrimental to business.
Below diagram covers the steps that needed to be performed. Details of these items will be covered in a detailed blog and will be linked here soon.
Thanks for reading. We will be writing more articles on Applied ML as part of Learning ML – The applied Way series.